分享:实际业务里 work 的AI Agent客服系统(一)
在经历了三四轮失败后,我跑通了一套以 Agent 为核心、人工为辅助的进化系统。它的核心不在于初始配置有多牛,而在于一套“反馈-纠正-固化”的闭环评估机制,让 AI 能够在实战中不断“吃一堑长一智”。
过去一年的探索:从失败到真正 Work
heading.anchorLabel过去一周我一直在开发自己的客服系统。 这套系统以 Agent 为核心来解决问题,人工只是辅助。已经在实际业务场景里跑通了。目前看下来还是不错的。
其实用 AI 来解决客服问题,我从去年上半年就已经开始尝试。 经过三四轮的尝试,之前都失败了。 到了 26 年,它已经成功了,并且门槛并不高。
它是一个在实际业务场景中可以 Work 的系统。 得益于大模型和 Agent 系统形态的发展,现在这套系统已经可以在实际业务场景里面运行了。
今天就讨论一下:以 Agent 为核心的客服系统,它最核心的模块是什么,怎么设计。
真实世界:不存在完备的知识库和工具集
heading.anchorLabel我认为 Agent 客服系统最核心的就是解决一个问题: 怎么让这个 Agent 不断地升级,提升自己的能力,来覆盖更多的对话场景,从而减少对人力的需要。
从理论上来讲,只要准备非常完备的知识库,提供非常完备的工具,它就能覆盖更多场景。 但在实际业务中,这是不可能的。
- 人性使然: 在没有业务倒逼的情况下,没有人愿意整理那么多知识库,也没有人愿意做那么多工具。
- 必须实战: 即便把历史问题全部捞出来,也只是纸上谈兵,用起来总有各种问题。
所以关键在于:如何让 Agent 在实际运行过程中不断地自我升级。
以评估为驱动:优化升级的三大环节
heading.anchorLabel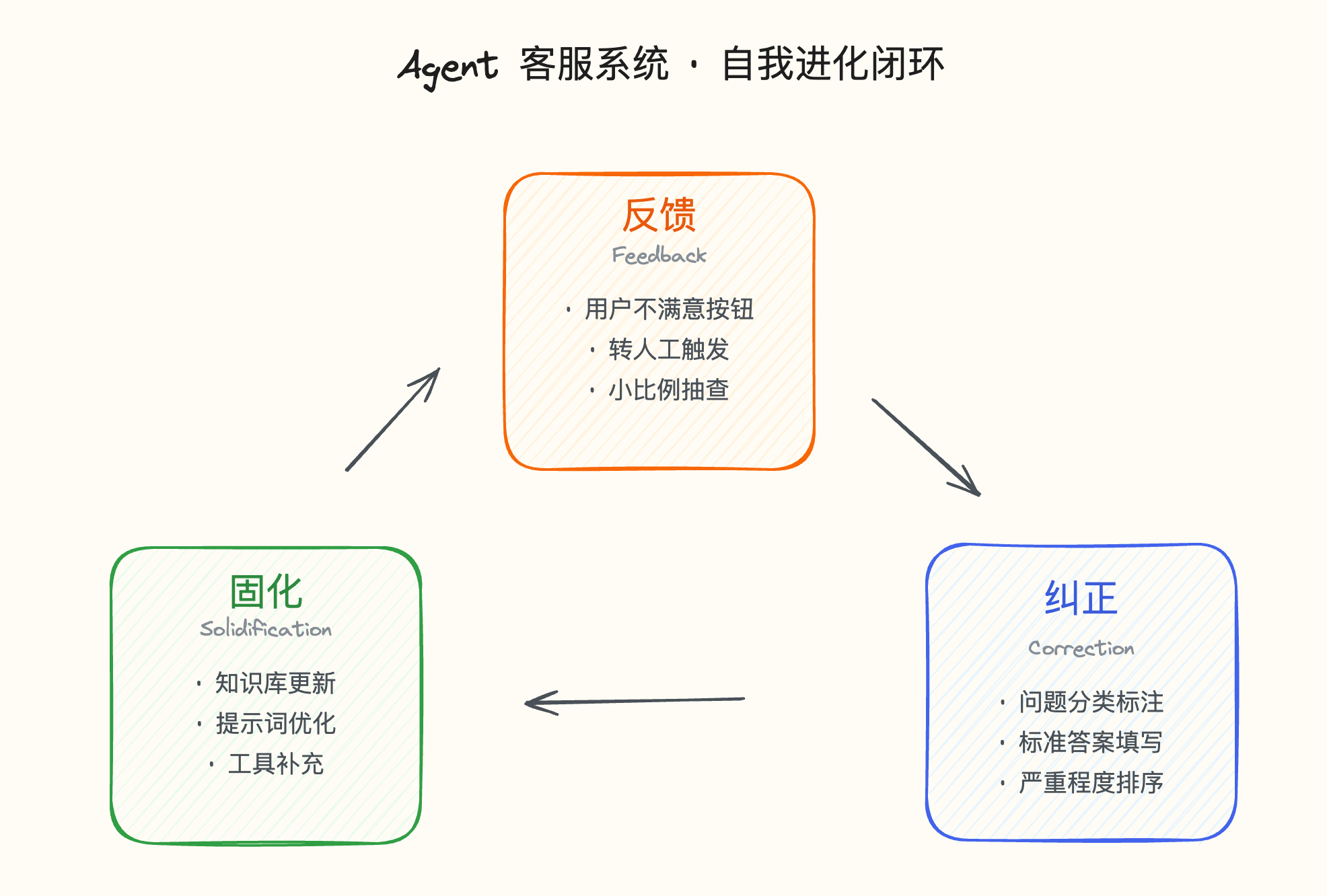
这里面最关键的是基于评估手段,通过评估来驱动系统优化,而不是把锅甩给知识库和工具。
这套方案最重要的有三个环节:
- 反馈环节
- 纠正环节
- 固化环节
反馈环节:捕捉那“1%”的有效信号
heading.anchorLabel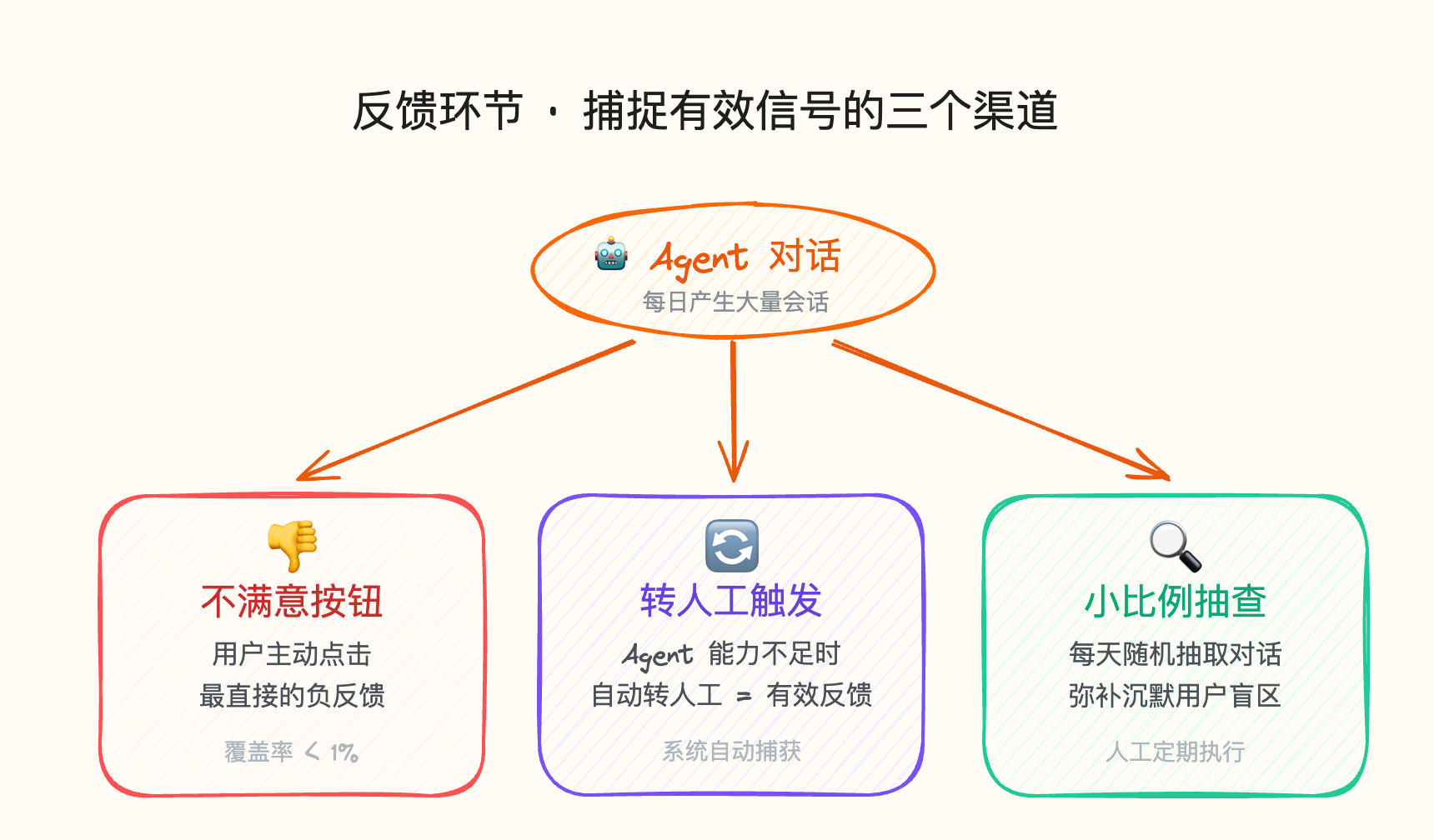
反馈环节就像写作业,正确的题不需要反馈,只有错题才需要纠正。 但靠用户打分的比例太低了,可能不到 1% 的用户愿意评分。
为了获得有效反馈,我设计了三个渠道:
- 用户明确不满意的记录: 在每一个对话下面设计一个“不满意”按钮。只要用户点击,系统就会记录。
- 转人工触发: 我的提示词里只要超出 Agent 能力范围转了人工,就意味着 Agent 搞不定,这必须成为一个有效反馈。
- 小比例抽查: 针对每天 Agent 的对话进行小比例抽查。因为总有人即便不爽也不会说,抽查是一个必要的补充。
这是整个系统最重要的起点。
纠正环节:人工到底该如何纠正?
heading.anchorLabel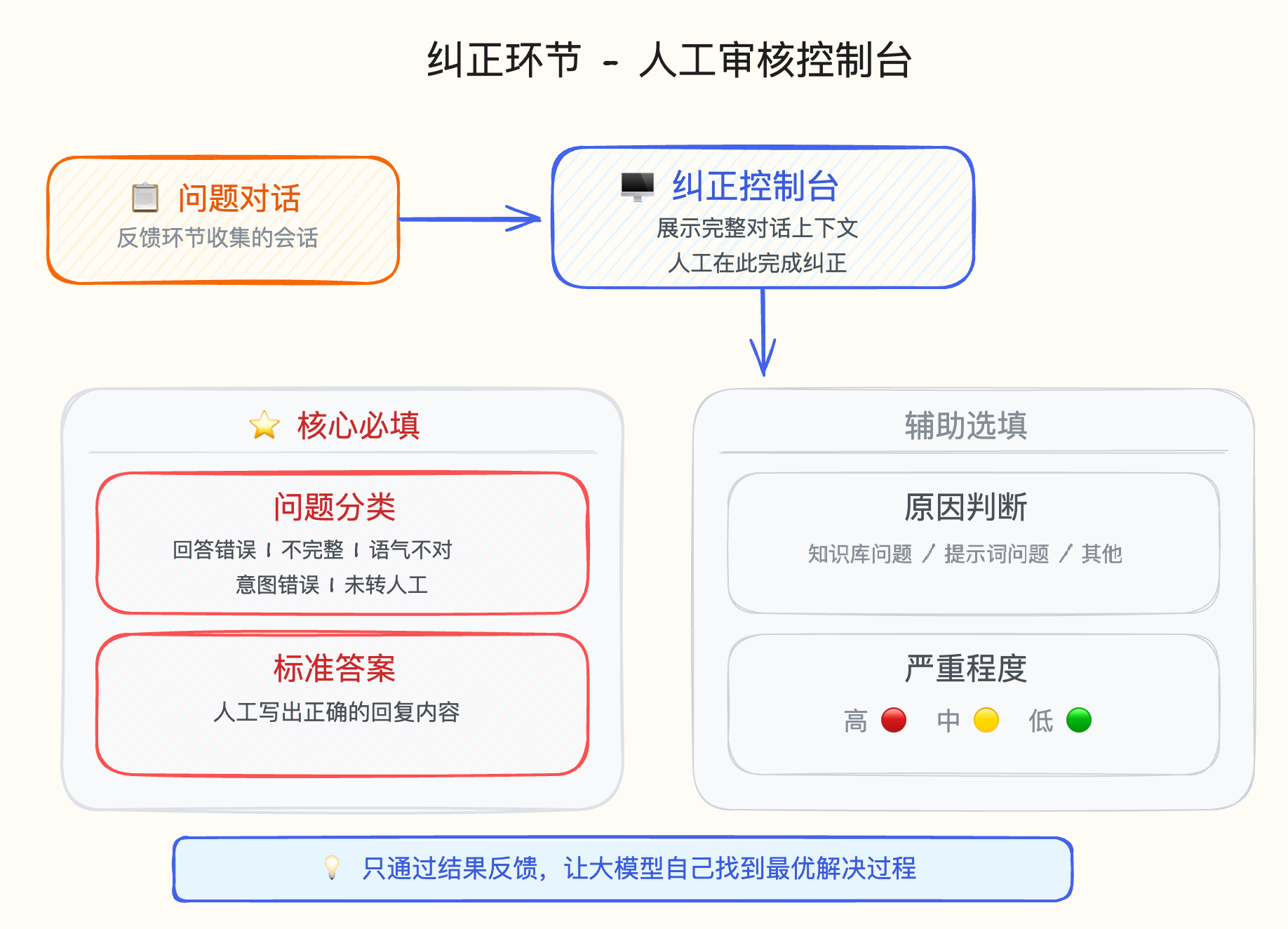 纠正环节就是把上述反馈的对话上下文全部丢进一个控制台,让人工去纠正。 人工在这里要发挥巨大的作用。
纠正环节就是把上述反馈的对话上下文全部丢进一个控制台,让人工去纠正。 人工在这里要发挥巨大的作用。
我们实践下来,有两类核心信息必须明确:
- 问题分类: 到底是回答错误、不完整、语气不对、意图理解错误,还是该转人工没转?
- 标准答案: 如果 Agent 回答错误,人工需要详细写出正确的答案。
除此之外,还有一些辅助选填项:
- 判断产生问题的原因(知识库问题、提示词问题或其他)。
- 问题的严重程度排序(高、中、低)。
核心中的核心,依然是“分类”和“正确答案”。现在大模型的能力不断提升,我们不要去限制整个大模型处理的过程。
只通过结果给Agent做反馈,大模型自己能够找出最好的解决方案过程。
固化环节:让 AI 给出建议,由人最后把关
heading.anchorLabel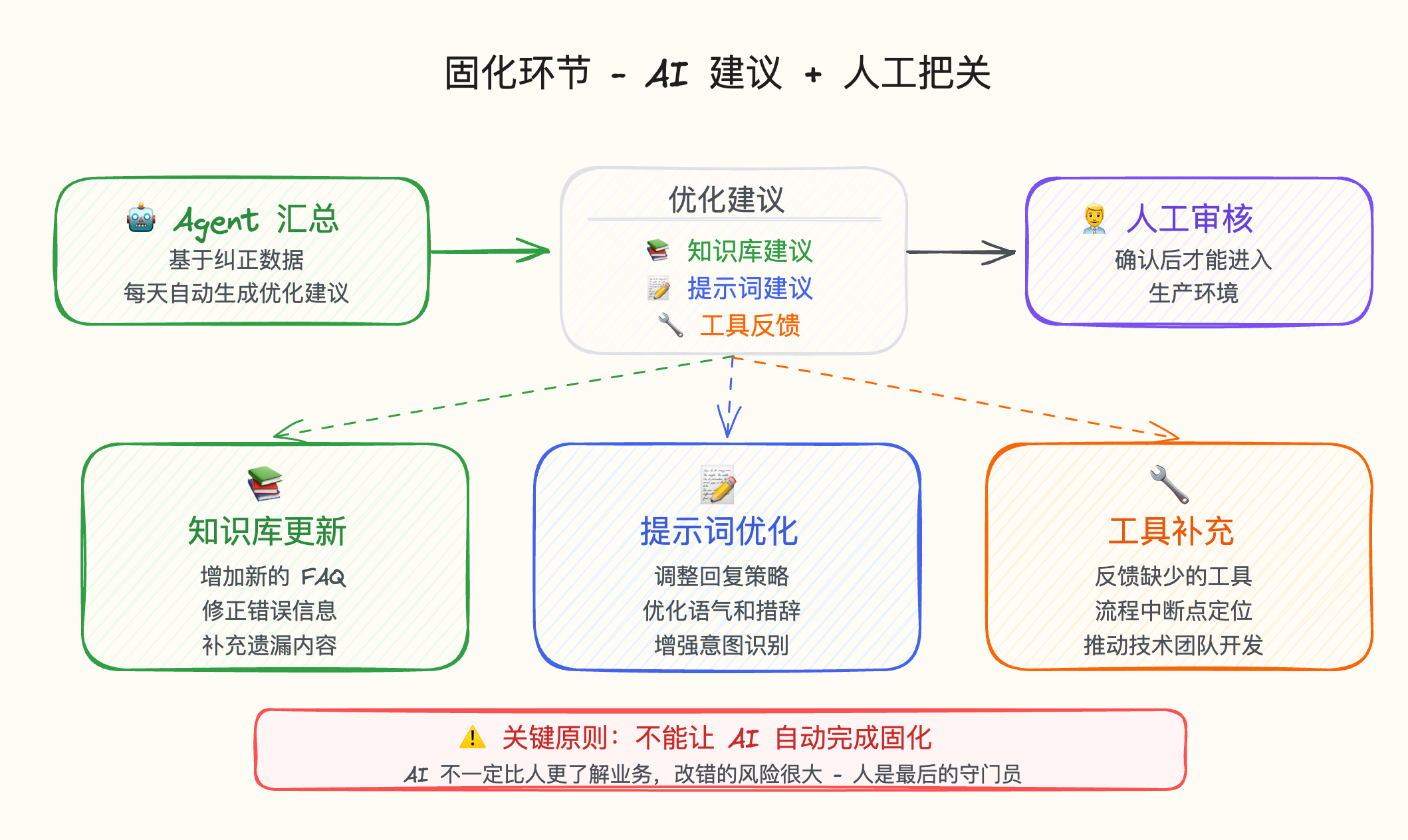
有了反馈和纠正,怎么让未来不再出现相似问题?这就是固化。
任何问题的优化最终都会落实到三个落地处: 知识库、提示词、工具调用。
但如果全靠人去优化这三项,效率太低了。 现在的设计是:由 Agent 基于人工纠正的信息,每天汇总一遍优化建议给到人工审核。
- 知识库建议: Agent 提议增加或修改哪些内容,人来审核。
- 提示词建议: Agent 给出修改方案,人来审核。
- 工具反馈: 反馈现有流程中缺少哪些工具或信息。
最重要的一点:不能让它自动完成。 在实际业务里,AI 并不一定比人更了解业务,很可能改错。 人作为最后的审核人员,确定优化后的内容才能进入生产环境。
结语:寻找 Agent 与人工的平衡点
heading.anchorLabel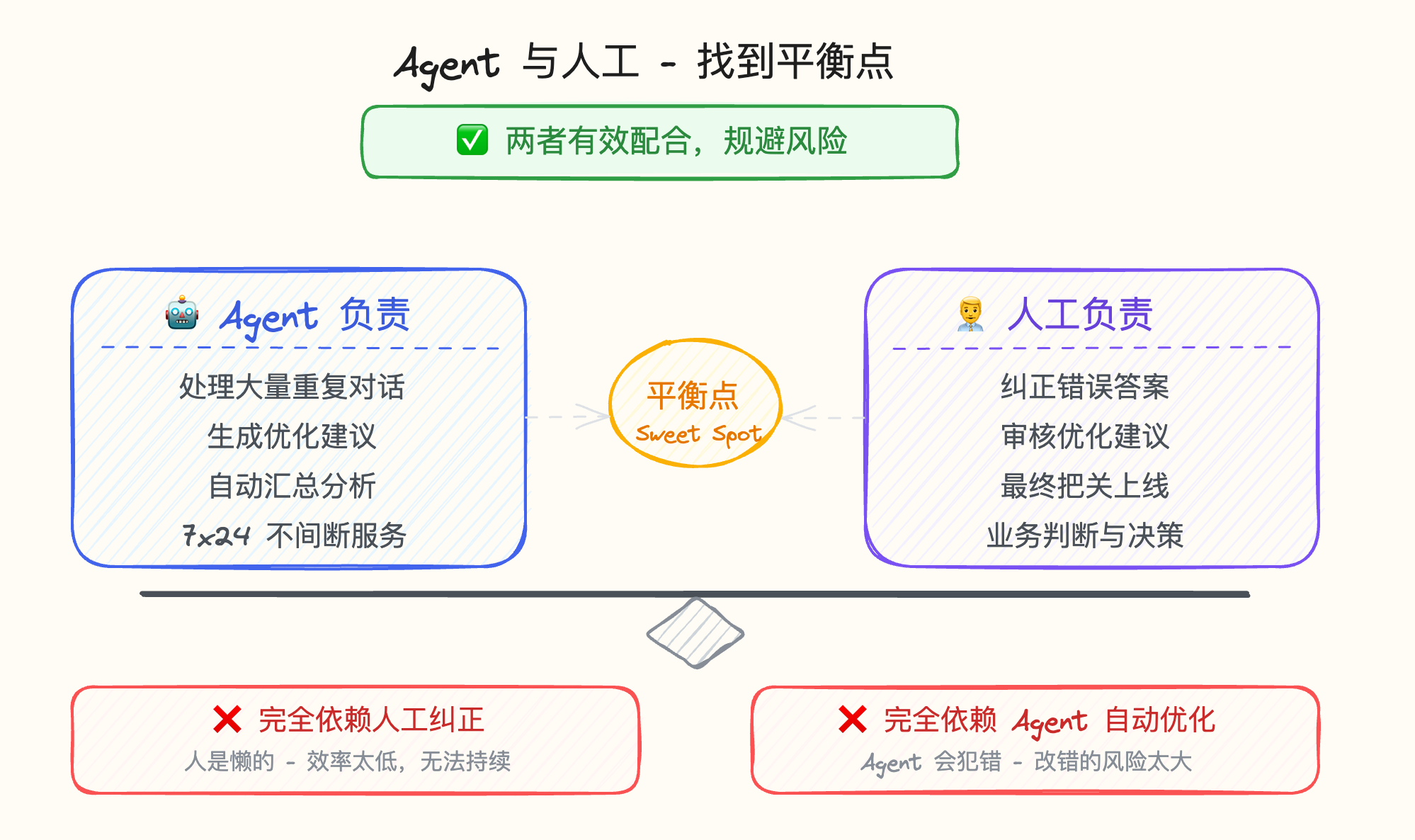
这就是一套完整的、基于评估驱动的 Agent 自我优化系统。
它在实际业务场景中操作并不复杂,也没有过度依赖人工。 它找到了 Agent 和人工之间的一个很好的平衡。
网络上有很多高大上的方案,但我认为都存在风险。
因为最真实的场景是:人是懒的,Agent 是会犯错的。
完全依赖人工纠正不靠谱,完全依赖 Agent 自动优化也不靠谱。 两者有效规避风险,这套系统才能行之有效。