比提示词更重要!3个技巧教你用好AI的「上下文」
- Home
- AI 知识库
- LLM大模型
比提示词更重要!3个技巧教你用好AI的「上下文」
Section titled “比提示词更重要!3个技巧教你用好AI的「上下文」”文章目录
引言:别再迷信“神级提示词”
Section titled “引言:别再迷信“神级提示词””很多人用AI大模型时,总觉得如果AI回答不好,是因为自己的“咒语”(提示词)念得不对。大家拼命在网上找各种“神级提示词模板”,试图用一句话解决所有问题。 但其实,决定AI回答质量的,往往不是你输入的那一句话,而是多轮对话的过程「上下文」(Context)。 我们在实际使用AI的过程中,不可能一句提示词就能得到我们想要的东西,而是通过多轮对话,不断调整才能唠出好东西。
一、 上下文 VS 提示词:一次性指令与连续对话
Section titled “一、 上下文 VS 提示词:一次性指令与连续对话”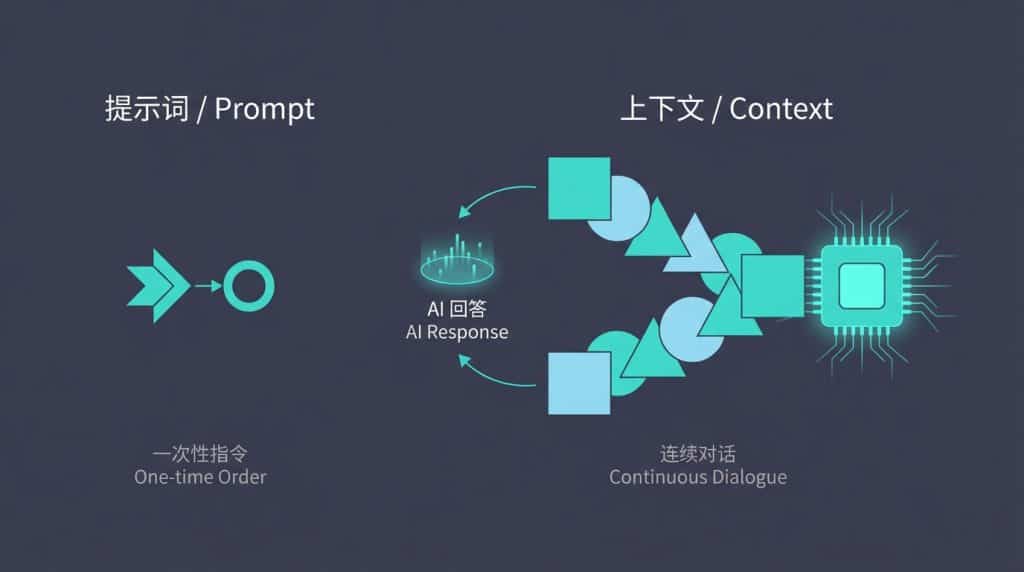 我们最容易犯的错误,就是把AI当成搜索引擎用:问一句,回一句,用完即走。
但大模型最厉害的地方在于多轮对话。
我们最容易犯的错误,就是把AI当成搜索引擎用:问一句,回一句,用完即走。
但大模型最厉害的地方在于多轮对话。
- 提示词(Prompt): 就像是你对AI说的一句指令,一次性的。
- 上下文(Context): 是你们之前聊过的所有内容。它是连贯的、持续的。 如果把和AI聊天比作“带实习生”: 提示词只是你随口吩咐的一个任务;带过人的都知道,一句话根本搞不定实习生。 而上下文,是你给实习生看的所有过往项目资料、会议记录和操作手册。资料越全、背景越清晰,实习生干活越靠谱。
二、 原理揭秘:AI其实是个“健忘症”
Section titled “二、 原理揭秘:AI其实是个“健忘症””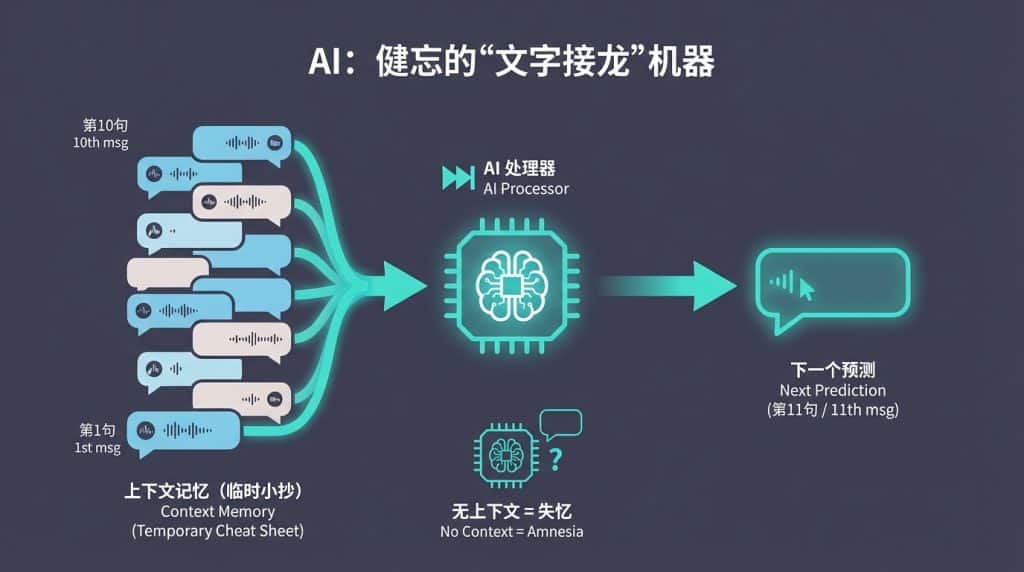 你以为AI像人一样,聊久了就有感情、有记忆?NONONO~
本质上,AI是一个没有任何记忆的“文字接龙机器”。
当你发出第10句话时,AI并不是“记住了”前9句话。实际上,系统是在后台把你这10句话打包,一股脑儿全塞给AI。AI必须以极快的速度,把这10句话从头到尾重读一遍,假装自己记得,然后预测出第11句话。
上下文,就是AI每次回答前必须复习的“临时小抄”。
没有这个小抄,AI瞬间就会失忆,连你是谁、刚才聊了什么都会忘得一干二净。
LLM 运作方式确实是 Autoregressive Generation (自回归生成) 或 Next-Token Prediction (下一个词元预测),即基于整个输入序列(含对话历史)来决定下一个输出。
《Attention Is All You Need》| ArXiv
你以为AI像人一样,聊久了就有感情、有记忆?NONONO~
本质上,AI是一个没有任何记忆的“文字接龙机器”。
当你发出第10句话时,AI并不是“记住了”前9句话。实际上,系统是在后台把你这10句话打包,一股脑儿全塞给AI。AI必须以极快的速度,把这10句话从头到尾重读一遍,假装自己记得,然后预测出第11句话。
上下文,就是AI每次回答前必须复习的“临时小抄”。
没有这个小抄,AI瞬间就会失忆,连你是谁、刚才聊了什么都会忘得一干二净。
LLM 运作方式确实是 Autoregressive Generation (自回归生成) 或 Next-Token Prediction (下一个词元预测),即基于整个输入序列(含对话历史)来决定下一个输出。
《Attention Is All You Need》| ArXiv
三、 警惕!上下文的“三大缺陷”
Section titled “三、 警惕!上下文的“三大缺陷””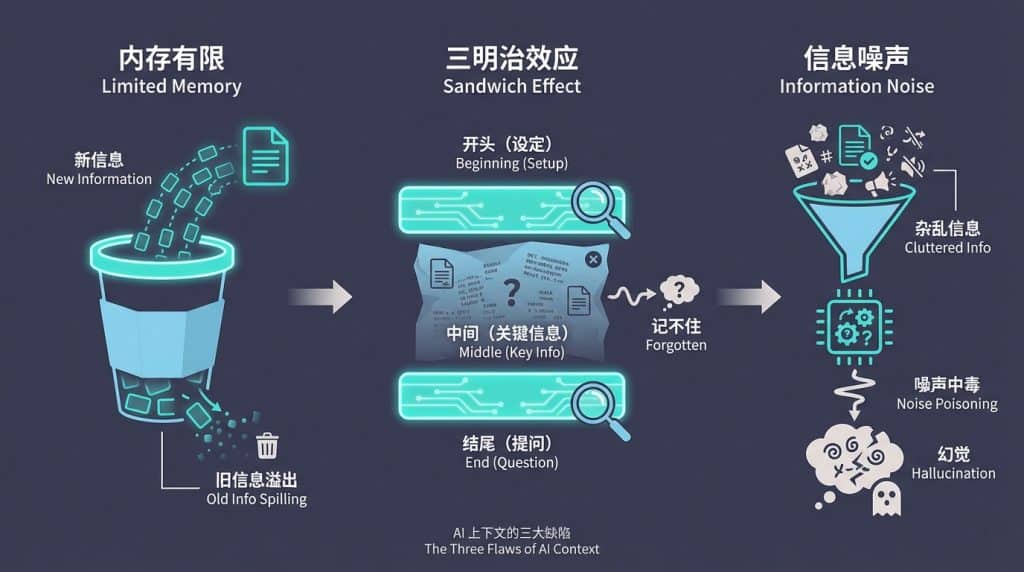 既然上下文是“小抄”,那是不是抄得越多越好?并不是。目前的AI模型在处理上下文时,有三个明显的短板:
1. 内存有限: 这个“小抄”是有字数上限的。如果你给的资料太多,超过了它的处理极限,最早的聊天记录就会被强行“挤”出去。就像一个装满水的杯子,新水倒进去,旧水就流出来了。
2. 三明治效应: 研究发现,AI对上下文的记忆主要集中在开头(最早的设定)和结尾(你最新的提问)。如果你把关键信息塞在几万字的对话中间,AI大概率会记不住的。
述了 LLM 在处理长上下文时,对开头(Primacy Bias/首因效应)和结尾(Recency Bias/近因效应)的信息召回率最高,而中间部分最差的现象。
《Lost in the Middle: How Language Models Use Long Contexts》| ArXiv
3. 信息噪声: 给的信息越杂,AI越容易晕。如果你在对话里塞了一堆无关的文档、乱七八糟的要求,AI就会“幻觉”,开始胡言乱语。这叫“噪声中毒”。
In-Context Learning (ICL) 对输入噪声(如不相关或错误的演示示例)的敏感性。不相关的文档或指令会分散模型的注意力,增加 Hallucination (幻觉) 的风险。
《On the Noise Robustness of In-Context Learning for Text Generation》|ArXiv
既然上下文是“小抄”,那是不是抄得越多越好?并不是。目前的AI模型在处理上下文时,有三个明显的短板:
1. 内存有限: 这个“小抄”是有字数上限的。如果你给的资料太多,超过了它的处理极限,最早的聊天记录就会被强行“挤”出去。就像一个装满水的杯子,新水倒进去,旧水就流出来了。
2. 三明治效应: 研究发现,AI对上下文的记忆主要集中在开头(最早的设定)和结尾(你最新的提问)。如果你把关键信息塞在几万字的对话中间,AI大概率会记不住的。
述了 LLM 在处理长上下文时,对开头(Primacy Bias/首因效应)和结尾(Recency Bias/近因效应)的信息召回率最高,而中间部分最差的现象。
《Lost in the Middle: How Language Models Use Long Contexts》| ArXiv
3. 信息噪声: 给的信息越杂,AI越容易晕。如果你在对话里塞了一堆无关的文档、乱七八糟的要求,AI就会“幻觉”,开始胡言乱语。这叫“噪声中毒”。
In-Context Learning (ICL) 对输入噪声(如不相关或错误的演示示例)的敏感性。不相关的文档或指令会分散模型的注意力,增加 Hallucination (幻觉) 的风险。
《On the Noise Robustness of In-Context Learning for Text Generation》|ArXiv
四、 高手秘籍:3招用好上下文
Section titled “四、 高手秘籍:3招用好上下文”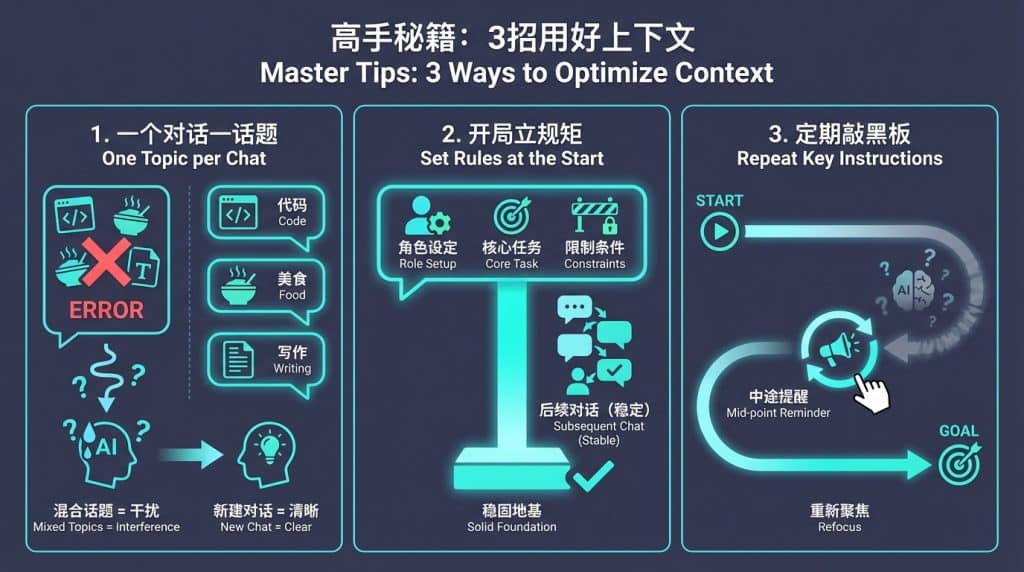 理解了原理,我们就能对症下药。普通人只需掌握这3个技巧,就能大幅提升AI的智商。
理解了原理,我们就能对症下药。普通人只需掌握这3个技巧,就能大幅提升AI的智商。
技巧 1:一个对话只聊一个话题
Section titled “技巧 1:一个对话只聊一个话题”不要在一个对话框里聊所有事情。
- 错误做法: 上一秒让AI写代码,下一秒问它红烧肉怎么做,接着又让它翻译论文。这会导致“小抄”里充满了无关信息,干扰AI判断。
- 正确做法: 新建对话(New Chat)。 写代码开一个窗口,写文案开一个窗口。每次点击“新建对话”,就相当于给AI换了一本崭新的、干净的“小抄”,让它没有任何负担地开始工作。
技巧 2:开局“立规矩”,重要信息全部说完
Section titled “技巧 2:开局“立规矩”,重要信息全部说完”既然AI有“三明治效应”,记得住开头,那我们就把最重要的信息放在第一条提示词里。 在对话开始的第一次输入中,你要明确告诉AI:
- 你是谁(角色设定,如:你是一个资深翻译)
- 你要干什么(核心任务)
- 有什么限制(不要废话,只输出结果) 把地基打牢了,后面的楼才不会歪。不要等到聊了一半,才想起来补充核心要求。
技巧 3:定期“敲黑板”,重复关键指令
Section titled “技巧 3:定期“敲黑板”,重复关键指令”如果你的对话很长(比如让AI写长篇小说或处理超长文档),聊到后面AI开始跑题、变笨了,怎么办? 不要骂它,它只是忘了,或者搞不清楚重点了。 你需要充当“课代表”,在对话中途总结一下之前的进度,或者把最开始的要求再发一遍。 话术示例: “为了避免你忘记,我重申一下我们的目标是XXX,刚才我们已经完成了YYY,接下来请继续做ZZZ。” 这相当于强行把关键信息再次写到“小抄”的末尾(最新位置),强迫AI重新聚焦。 总结一下: 用好AI,不要只纠结由于那一句“提示词”写得够不够NB。管理好「上下文」,保持对话环境的纯净、关键信息的突出,才是让AI持续输出高质量内容的秘诀。 2025年12月1日 by 打不死的小强
Section titled “如果你的对话很长(比如让AI写长篇小说或处理超长文档),聊到后面AI开始跑题、变笨了,怎么办? 不要骂它,它只是忘了,或者搞不清楚重点了。 你需要充当“课代表”,在对话中途总结一下之前的进度,或者把最开始的要求再发一遍。 话术示例: “为了避免你忘记,我重申一下我们的目标是XXX,刚才我们已经完成了YYY,接下来请继续做ZZZ。” 这相当于强行把关键信息再次写到“小抄”的末尾(最新位置),强迫AI重新聚焦。 总结一下: 用好AI,不要只纠结由于那一句“提示词”写得够不够NB。管理好「上下文」,保持对话环境的纯净、关键信息的突出,才是让AI持续输出高质量内容的秘诀。 2025年12月1日 by 打不死的小强”LLM大模型
Section titled “LLM大模型”llm, prompt, 上下文, 大模型, 提示词 Thanks for your rating! You have already rated this article An error occured, please try again later
Was This Article Helpful?
Section titled “Was This Article Helpful?”2
这篇文章讲了什么?
Section titled “这篇文章讲了什么?”本文介绍了相关AI概念的基本原理和应用场景。
有什么实际应用?
Section titled “有什么实际应用?”该技术在计算机视觉、自然语言处理、推荐系统等领域有广泛应用。